LilSteve CS 175: Project in AI (in Minecraft)
Final Video
Summary of the Project
From its in-game soundtrack to jukeboxes and noteblocks, Minecraft’s music is an iconic component of the game’s history. A quick YouTube search demonstrates the popularity of Minecraft’s music with the top videos garnering hundreds of millions of views. Minecraft noteblock circuit videos are no exception to this phenomenon as millions of viewers show up to listen to the Minecraft rendition of their favorite song. In addition to the actual songs, tutorials about creating noteblock circuits that replicate various songs are also immensely prevalent, illustrating the demand for this type of content. However, while detailing the steps that are necessary to create noteblock circuits, these videos also note that the creation process often takes many hours to even days in order to complete. Therefore the construction of a product that enables users to enjoy their favorite songs within the beauty of Minecraft’s music without the exorbitant time sink is one that is not only practical but also fills a massive demand.
The goal of our project is to take in a song as input and create a noteblock representation of that song in Minecraft. The input is any audio file chosen by the user. The Minecraft representation of the song consists of a series of note blocks connected into a redstone circuit that plays the completed song when powered. The type of Minecraft block that is placed underneath each note block determines the sound that the note block creates. In order to make our representation of the input song sound as close as possible to the original, we are using machine learning algorithms to choose the correct type of block to place under each note block.

(Minecraft Circuit Program Output)
Our project is essentially split into two parts, both of which are certainly not trivial, and required a lot of work to complete. The first challenge we had to solve was figuring out when each note was being played and which note was being played at that particular time. In order to do this, we used Neural Networks through AnthemScore, and this mapping from time to notes was necessary and used for each of the models that handled the second aspect of this project. The second piece that we needed to work out was determining which instrument was being played at which time. To do this, we used Random Forests and Neural Networks, and we placed the corresponding block below note blocks to create the desired sound. Both of these tasks required machine learning because they involved the recognition of various patterns and sound in order to recognize the start of notes and the sound of instruments.
Approaches
Note Type and Timing
One of the first tasks that we had to accomplish was to be able to detect when each note of a song was being played. The first way that was attempted to do this was by looking at the csv representation of the song produced by anthem score. The approach that was taken when analyzing the csv file representation of the song from Anthemscore was to extract the maximum amplitude that was recorded at each millisecond of the audio file. This data could then be visualized as a graph of amplitude over time. In this approach, the local maxima in the graph would be the time that a note was played, and the frequency corresponding to the column in the csv file would be the frequency of the note that was played. This approach in identifying specific notes of a song produced an audio representation that was unrecognizable as the original song, so we had to take a different approach using the xml file.
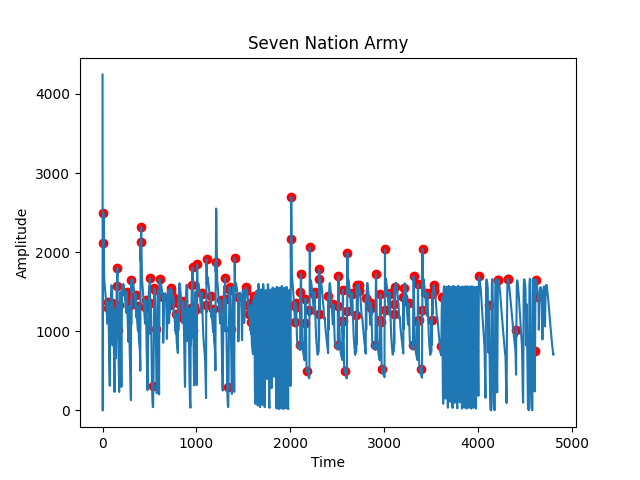
(Amplitude Graph)
To generate data for this project, we sent in an audio file into AnthemScore, which is a software that uses neural networks to generate spectrograms, sheet music, and other interesting types of data. We mainly focused on the spectrograms and the xml files in our project to give us a better understanding of what kind of sounds are occurring at what point in the audio file. After retrieving the spectrogram data, we parsed the data so that we only have data for the intervals we are interested in. We did this by using a simple formula:
Seconds per 16th note = 15 / BPM
The value we get from this formula will indicate how many rows we would need to skip by, since each row of the csv file indicates a hundredth of a second.

(AnthemScore Representation of Notes)
Random Forest Classifier
One approach we tried was to send the values of the csv file into multiple Random Forest Classifiers to train each classifier on when an instrument is being played. To do this, we first generated test audio data from a Digital Audio Workstation (DAW) called Ableton. Then, we send it to AnthemScore to generate the csv file, and parse it as mentioned before. Then we created an excel sheet that indicates when each instrument was being played on 16th note intervals for all of the samples. Then we use this data with the data from the csv file to train a Random Forest Classifier for each instrument sound that is in Minecraft. Next, we passed in the test audio file into AnthemScore to generate the csv and xml files. Then, we send the parsed csv file to each classifier to get a list of predictions for each 16th note interval in the song, and we use the xml file as a guide to calculating what bass and piano notes are being played during each 16th note interval of the song.
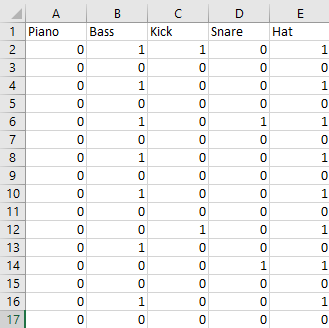
(Example of the personally generated excel sheet)

(Sample of the xml file)
Neural Networks
The idea behind the Neural Network model was to split the song into the five instruments that Minecraft supports, and then figure out which ones were playing at which times. In terms of splitting the song up, the goal was to have the original song as input, and to output five files, each containing only one instrument. The aim was to have each file have the instrument playing at the time it is playing during the original song, and to have the audio file be silent when that instrument is not playing. Then once we have all of the instrument files, we can take our AnthemScore mapping of notes being played at specific times, and use the split up song to see which instrument is playing which notes. To do this, we first run each of the five files through AnthemScore to get a csv file for each instrument containing the amplitude of every frequency for every 0.1 second interval. After we get the csv files, we can look at each time point where a note is being played, given by the Note Type and Timing section above, and if the amplitude of an instrument at that time point is above a certain threshold, we can say that the instrument is being played, at the pitch also given by the Note Type and Timing section above. This threshold is specific for each instrument, meaning that every instrument will have a different threshold. To calculate the threshold, we first go through the csv file and get the average amplitude throughout the entire song for that instrument. Then we calculate the standard deviation by taking each amplitude, subtracting it by the average, squaring that value and summing each of these squared differences up. To get the final standard deviation, we take this summation, divide by the total number of values, then take the square root. We then multiply the standard deviation by seven, and add that value to the mean to get the threshold. The reason we want the threshold to be so large is because there may be bleeding from other instruments into the instrument that we are looking at. As a result, we do not want any false positives caused by other instruments, so we only want to take amplitudes that are exceptionally high, such as ones that are seven standard deviations above the mean. Also, for these instrument files, a lot of the time they will be silent, which will drag the mean down, meaning that seven standard deviations above the mean does a good job of finding points where instruments are actually being played. Then, based on the instrument that is playing, we can place a block underneath the note block in order to create the desired sound.

(NN Model training)
The reason this is called the Neural Network model is because we used Neural Networks to split the song into the five different instrument files. To do this, we first created twenty different songs using Ableton in order to allow the model to train. Each of the songs had six components: a snare, kick, hi-hat, bass, piano, and mix. The snare, kick, hi-hat, bass, and piano each had their own separate files for each of the twenty songs, and the mix contained all of the instruments together for each song. Then, to split the song up into separate tracks, we input the twenty sample songs into our Neural Network model with a learning rate of 0.0001 and a maximum number of training steps for each song of 1000. Then meant that with each song that was added, the amount of training that would be done scaled up considerably. We used ELU as our activation function, which has the equation :
The derivative of this equation is fed into the backpropagation algorithm during learning. This is:
After training, we pass the user’s input song into our model, and we get the split instrument files as our output which we can then pass to AnthemScore as described above.

(Activation Function and Derivative)
Advantages and Disadvantages
Generally speaking, Random Forest Classifiers are less prone to overfitting and not as computationally expensive as Neural Networks. In fact, one of the biggest selling points for Random Forest Classifiers is their ability to avoid overfitting, through the use of bagging, and their lightweight nature, by taking many less sophisticated classifiers and combining their power. Also, Neural Networks often require a lot of training data and usually perform worse than Random Forest Classifiers without it. On the other hand, Random Forest Classifiers can manage fairly well without an abundance of training data. However, it is not all bad for Neural Networks as they are able to learn by themselves and produce output that is not limited by the input. The issue is that this takes a lot of time and computation power to achieve, whereas Random Forest Classifiers are much faster and simpler in that respect. As an example, for this project, our Random Forest Classifier took around one minute to complete training on four songs, but our Neural Network model exhausted battery life, occupied 100% of the computer, and took around eight hours to complete training on eight songs. Despite their downfalls though, Neural Networks have a higher ceiling than Random Forest Classifiers, and with unlimited time and resources, we believe the Neural Network model would outperform the Random Forest Classifier. However, these resources are finite, and must be taken into account when comparing the two approaches.
Evaluation
Random Forest Classifier
Quantitative Analysis
Again, getting a spot-on quantitative evaluation of our project is a tough task. Since we are limited with what kind of instrument, tempo, and meter we can use, we are limited with what we can evaluate as well. Since we used the YouTube video, it’s impossible to tell exactly when each instrument is being played, but we can get a good estimate with a little bit of music knowledge. We created an excel sheet for the expected values for each instrument, and compared them with the output of the Random Forest Classifiers to get an estimate of the accuracy of our models. We were able to achieve an overall accuracy of 91%, but despite its accuracy, the song was still unrecognizable in some parts. However, although it was not a perfect model, we believe that the performance could be improved by using more test data.

(Random Forest Accuracy)
Qualitative Analysis
On the qualitative aspect, the song generated by the model is recognizable, at best. Initially, we attempted to decipher which notes were being played by inspecting the spectrogram generated by AnthemScore, but after adding multiple instruments into the picture this became more difficult to do, and the songs on Minecraft became more and more unrecognizable. For this reason, we proceeded to rely on AnthemScore’s xml file, which had more accurate predictions of the pitches of the notes. The famous bass line of the song is audible, but the subtler vocals are more scattered and less accurate. However we believe that with more training data, the performance of the classifier could be boosted even more.
Neural Networks
Quantitative Analysis
In order to evaluate our Neural Network model quantitatively, we followed a similar procedure as what we did to evaluate our Random Forest Classifier. This means that we created an excel sheet for the expected values for each instrument, and compared them with the output of the Neural Network model. We made sure to be consistent with our evaluations in order to make comparing the two models seamless and easy to understand. With only one song, the Neural Network model only achieves 61.19791666666667% accuracy, which is not very high considering randomly guessing yes or no would yield approximately 50% accuracy. With eight songs, the model achieves 86.63194444444446% accuracy, which is a nice significant increase over the one song model, however the improvements begin to slow down after this stage. Finally, with all twenty training songs, the model achieves 93.2291666666667% accuracy.

(Neural Network Accuracy)
Due to this slow down in accuracy gain, it appears from the graph that to get a very high accuracy, in the range of 97-99%, the model would require over 100 songs to train on. However, due to limitations in equipment, this would take an egregious amount of time, on the order of several weeks straight, which is unrealistic currently. Another way to increase the accuracy of the classifier would be to increase the maximum number of training steps for each song from 1000 to something like 10000. However attempting to do this on the current hardware at our disposal took over 24 hours for one song, and even so the model did not complete training. Therefore, to achieve around 93% accuracy is very strong all things considered.
Qualitative Analysis
Upon listening to the Minecraft circuit that is output by the Neural Network model, it is certainly clear that the input song is Seven Nation Army. The note blocks are consistently accurate, which is to say that there are no points where the circuit sounds immensely different to the original input. However, the output is not 100% accurate, so there are areas where some notes are missed, but because these are few and far between, it is not overly noticeable. Furthermore, the fact that these mistakes occur throughout the song, rather than in one specific area, makes the errors even less noticeable. Generally, the piano and bass sound extremely accurate due to the fact that AnthemScore is able to handle these instruments very well, and also because the Neural Network separator does a very good job at separating these instruments. The reason that the separator is able to isolate these instruments well is because they sound fairly different from the other instruments, whereas the separator has a more difficult time separating the drums from each other. The model is able to separate the drums from the piano and bass well, but when listening to the different isolated drums, there is a bit of bleed through from the other drums. This is the case because for the most part, drums follow certain patterns and sound relatively similar, especially snares and hi hats, which makes it more difficult to distinguish between them. However, the model generally does a good job, and because snares and hi hats sound relatively similar, when the model mixes them up, it is not a very noticeable mistake in the output.
Comparison
Quantitative Analysis
Compared to the Neural Network model, the Random Forest Classifier trains at a much faster rate, and this phenomenon is clear when looking at the two line graphs above. To achieve 91% accuracy, the Random Forest Classifier only needs four songs, compared to the 20 songs needed by the Neural Network Model to achieve a similar performance. On top of this, the time it takes the Random Forest Classifier to train on each song is considerably less than the time it takes for the Neural Network model. To put this into a quantitative perspective, it takes around one minute for the Random Forest Classifier to train on four songs, whereas it takes around eight hours for the Neural Network model to train on eight songs, which only gets to about 86.6% accuracy. In comparison to the Neural Network model, the Random Forest Classifier provides an incredible upgrade in both time and resources required to train and execute. This discrepancy is likely due to Random Forests being extremely light weight, especially compared to the notoriously lethargic Neural Networks, and it is worth noting that a lot of their benefit comes from the fact that they are a conglomeration of relatively simple models that use their sheer quantity to predict accurately, whereas Neural Networks do not have this luxury.
Qualitative Analysis
Although the final accuracies for Random Forest Classifier and the Neural Network model are similar, their outputs are not similar in sound. Here, we have a case where the quantitative analysis and the qualitative analysis of the two models tell a very different story from each other. At first glance, looking at the final accuracies, one would assume that the two models would produce similar sounding circuits, however they differ in a highly impactful manner. Where the Neural Network model is generally consistent with where it makes errors, the Random Forest Classifier is essentially the complete opposite. The Neural Network model will be hitting 93% of the notes throughout the entire song, whereas the Random Forest Classifier will get through 91% of the song completely perfectly, then miss the entirety of the last 9%. This is impossible to see through only a quantitative analysis, however after listening to the different circuits, this becomes clear. A potential explanation for this is that the Random Forest Classifier only trains on four songs, so it has familiarity with the areas that it gets right, but then when a section of the song comes that is unlike anything it has seen before, the Random Forest is unable to accurately predict the instruments. On the other hand, the Neural Network model has trained with 20 songs, so there is not large section such that it has never seen anything similar, but because Neural Networks need so much time and computational power to train, and because we could not provide this due to limited resources, the Neural Network model consistently missed instruments along the way. However, despite this, the two models do an incredible job and get above 90% accuracy regardless. Additionally, the two output circuits sound like the original song, and our original goal was achieved.
References
https://minecraft.gamepedia.com/Note_Block
https://www.lunaverus.com/
https://www.ableton.com/
https://sefiks.com/2018/01/02/elu-as-a-neural-networks-activation-function/
https://github.com/deezer/spleeter
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html